DICTIONARIES, also called maps, are unordered collections that store key-value pairs, where each value is associated with a unique key.
Each element in a dictionary has a unique associated key. The key is used to quickly access and look up the corresponding value.
Like their “siblings” HASH SETS, DICTIONARIES use an internal hash structure which allows fast and efficient value lookup and retrieval.
Therefore, the only operations a DICTIONARY allows are adding, removing, and checking for the existence of an element in the collection.
Playground
Properties
| Property | Dictionary |
|---|---|
| How often you’ll use it | 🔺🔺 |
| Is mutable | ✔️ |
| Is ordered | ❌ |
| Is indexable | 🟡 |
| Allows duplicates | ❌ |
When to Use a Dictionary
DICTIONARIES are your best ally in terms of search efficiency. Many, many algorithms and programs improve simply by using a dictionary correctly.
DICTIONARIES serve to build indexes. Imagine a book where you have an index, which allows you to quickly find which page to go to to read something (it’s something similar).

Now suppose you have a collection of people, and you want to search for them by their ID number. You have many, many people (one million) and you need to access them many times, always searching by ID.
In this case, having an Array with all the people and searching through the million people each time will kill your program’s efficiency.
It’s much better if you pre-calculate a dictionary, where you store the ID-Person relationship. Now, searching for a person by ID is almost instantaneous. In this way, it’s a kind of “cache” to improve searches.
Obviously, if you only have to search once, it’s not worth building a dictionary. Because building the DICTIONARY has a cost; you have to go through the entire collection and fill the dictionary.
Similarly, if your collection only has 10 people, you won’t notice a big improvement either. You might notice it, but you won’t dazzle anyone.
But if you have to search multiple times, in a “moderately long” collection, the DICTIONARY is your star collection.
Dictionary Examples in Different Languages
The syntax for using a dictionary can vary depending on the programming language. Below we will see examples in some popular languages:
// Declaration and use of a dictionary in :lang[C#]
Dictionary<string, int> ages = new Dictionary<string, int>();
ages.Add("Luis", 25);
ages.Add("María", 30);
ages.Add("Pedro", 28);
Console.WriteLine(ages["Luis"]); // Prints 25
// Declaration and use of a dictionary in :lang[C++]
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{
unordered_map<string, int> ages;
ages["Luis"] = 25;
ages["María"] = 30;
ages["Pedro"] = 28;
cout << ages["Luis"] << endl; // Prints 25
return 0;
}
// Use of a dictionary in :lang[JavaScript] (through an object)
const ages = {
Luis: 25,
María: 30,
Pedro: 28,
};
console.log(ages["Luis"]); // Prints 25
# Use of a dictionary in :lang[Python]
ages = {
"Luis": 25,
"María": 30,
"Pedro": 28,
}
print(ages["Luis"]) # Prints 25
In the previous examples, we create a dictionary and add key-value pairs to it. Then, we access the corresponding value using the key.
Internal Operation Advanced
Internally, a DICTIONARY works similarly to a HASH SET. Both use a hash function to assign a unique key to each value and store it in a specific location in the data structure.
However, unlike a HashSet which uses the element we want to store itself as the key, the dictionary uses another independent value to calculate the Hash.
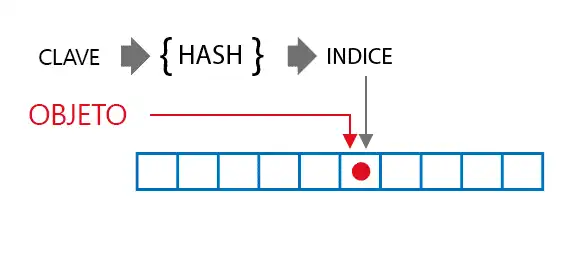
When a key-value pair is added to the DICTIONARY, the hash function is applied to the key to determine its storage location. Then, in this position, the element we are adding is stored.
If at any point the DICTIONARY becomes full, it automatically expands without us having to do it manually. At that moment, internally, all elements are copied to the new dictionary, and the hash functions are recalculated.
Efficiency
For a DICTIONARY, which is a data structure where elements are stored in key-value pairs, the table would look like this:
| Operation | Dictionary |
|---|---|
| Sequential access | ⚫ |
| Random access | 🟢 |
| Add at beginning | ⚫ |
| Remove at beginning | ⚫ |
| Add at end | ⚫ |
| Remove at end | ⚫ |
| Random insertion | 🟡 |
| Random removal | 🟢 |
| Search | 🟢 |
In the case of a DICTIONARY, it doesn’t make sense to talk about sequential access, adding at the beginning, or removing at the beginning, since the elements are not in a specific order and cannot be accessed directly by index. It also doesn’t make sense to talk about adding or removing at the end, since the elements are not in a specific order.
It is possible to add elements “in the order they belong”. That operation is O(1), unless we have to expand the HASH SET in which case it’s O(n).
The most relevant operation for a DICTIONARY is search, which is based on hashing. This allows fast, constant-time access to search for elements by their value, which is O(1).
If you want to know more, check out this entry
