HASH SETS, also called simply Sets, are unordered collections of unique elements. This means there cannot be duplicates in a set and the order of elements does not matter. Internally, they are usually implemented using a hash table.
Therefore, the only operations allowed in a HASH SET are adding, removing, and checking for the existence of an element in the collection.
It uses a technique called hashing to organize elements internally, which allows for fast retrieval and very quick searching of elements.
Playground
Properties
| Property | Set |
|---|---|
| Frequency of use | 🔻 |
| Is mutable | ✔️ |
| Is ordered | ❌ |
| Is indexable | ❌ |
| Allows duplicates | ❌ |
When to use a HashSet
The main use of a HASH SET is efficient element search. Imagine you have a series of trading cards, and you want to know if you already have that card in your collection (the famous “got it, don’t got it” of children).

With a HASH SET, you put each card into the collection. It tells you very quickly (much faster than an Array) if you already have that card added previously.
The HASH SET allows you to store elements in a collection and know if you already have that element and retrieve it if necessary. Therefore, its main use is searching for elements, finding duplicates, etc.
Finally, the HASH SET has a “sibling”, the DICTIONARY. It operates quite similarly to a HashSet, but with key-value pairs.
HashSet Examples in Different Languages
The syntax for using a HashSet can vary depending on the programming language being used.
Below, we will see examples in some popular languages:
HashSet<string> names = new HashSet<string>();
names.Add("Luis");
names.Add("María");
names.Add("Pedro");
foreach (string name in names)
{
Console.WriteLine(name);
}
#include <iostream>
#include <unordered_set>
using namespace std;
int main()
{
unordered_set<string> names;
names.insert("Luis");
names.insert("María");
names.insert("Pedro");
for (const string& name : names)
{
cout << name << endl;
}
return 0;
}
const names = new Set();
names.add("Luis");
names.add("María");
names.add("Pedro");
for (const name of names)
{
console.log(name);
}
names = set()
names.add("Luis")
names.add("María")
names.add("Pedro")
for name in names:
print(name)
In the previous examples, we create a HashSet (using the HashSet class in C# and C++, and the Set object in JavaScript and Python) and add several elements to it. Then, we iterate over the elements of the HashSet and display them on screen.
Internal Operation Advanced
Internally, a HASH SET works similarly to a dynamic array, but it uses a hash function to generate the numeric indices for the elements.
A hash function is a function that takes an element as input and returns a numeric value associated with that element. This value is used to decide which bucket stores and searches for the object in the HashSet.
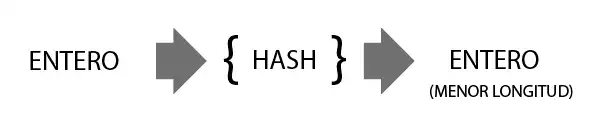
The “trick” of a Hash function is that it is designed to provide uniformly distributed results for the elements. It seems very complicated, but a simple example of a Hash function could simply be calculating the modulus of the element’s value (in binary) with respect to the size of the HASH SET.
When an element is added to the HASH SET, the hash function is applied to the object to determine its storage index. In the corresponding bucket, the element is saved if it does not already exist.
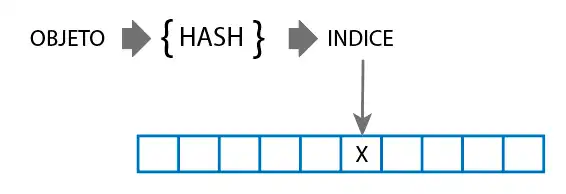
Now, if we need to check if our HASH SET contains an element, it calculates the hash function of the element and checks the corresponding bucket. If there are elements in that bucket, it compares them to know whether that specific element already exists.
If the HASH SET fills up when adding elements, since it’s a dynamic array, it expands dynamically transparently for the user. Additionally, the Hash function is changed for the new size, and all the Hashes of the stored elements must be recalculated.
This is also the reason why a HashSet has no order. Elements are stored internally “where they belong,” which has nothing to do with the order in which we introduced them.
The hash function ensures that elements are stored and searched efficiently, since the search is performed directly at the position calculated by the hash function, without the need to traverse all elements.
Efficiency
For a HASH SET, which is a collection where elements are unordered and duplicates are not allowed, the table would look like this:
| Operation | HashSet |
|---|---|
| Sequential access | ⚫ |
| Random access | 🟢 |
| Add at beginning | ⚫ |
| Remove at beginning | ⚫ |
| Add at end | ⚫ |
| Remove at end | ⚫ |
| Random insertion | 🟡 |
| Random removal | 🟢 |
| Search | 🟢 |
In the case of the HASH SET, it doesn’t make sense to talk about sequential access, adding at the beginning, or removing at the beginning, since elements are not in a specific order and cannot be accessed directly by index. It also doesn’t make sense to talk about adding or removing at the end, since elements are not in a specific order.
It is possible to add elements “in the order they belong.” That operation is O(1), unless we need to expand the HashSet in which case it’s O(n).
The most relevant operation for a HASH SET is search, which is based on hashing. This allows for fast and constant-time access to search for elements by their value, which is O(1).
If you want to know more, check out this entry
